Dit post maakt gebruik van spaCy, een populaire Python-bibliotheek die de taalgegevens en algoritmen bevat die je nodig hebt om teksten in natuurlijke taal te verwerken. Zoals u in dit post zult leren, is spaCy gemakkelijk te gebruiken omdat het containerobjecten biedt die elementen van natuurlijke taalteksten vertegenwoordigen, zoals zinnen en woorden. Deze objecten hebben op hun beurt attributen die taalkenmerken vertegenwoordigen, zoals delen van spraak. Op het moment van schrijven bood spaCy voorgetrainde modellen aan voor Engels, Duits, Grieks, Spaans, Frans, Italiaans, Litouws, Noors Bokmål, Nederlands, Portugees en meerdere talen gecombineerd. Bovendien biedt spaCy ingebouwde visualizers die u programmatisch kunt aanroepen om een grafische weergave van de syntactische structuur van een zin of benoemde entiteiten in een document te genereren.
De spaCy-bibliotheek ondersteunt ook native geavanceerde NLP-functies die andere populaire NLP-bibliotheken voor Python niet hebben. SpaCy ondersteunt bijvoorbeeld native woordvectoren in tegenstelling tot de Natural Language Toolkit (NLTK). Als u de laatste gebruikt, moet u
een tool van derden zoals Gensim, een Python-implementatie van het word2vec-algoritme.
Met spaCy kunt u bestaande modellen of individuele modelcomponenten aanpassen, en u kunt uw eigen modellen helemaal opnieuw trainen om aan uw wensen te voldoen toepassingsvereisten. U kunt ook de statistische modellen koppelen die zijn getraind door andere populaire machine learning-bibliotheken (ML), zoals TensorFlow, Keras, scikit-learn en PyTorch. Bovendien kan spaCy naadloos samenwerken met andere bibliotheken in het AI-ecosysteem van Python, waardoor u bijvoorbeeld kunt profiteren van computervisie in uw chatbot-applicatie..
Natuurlijke taalverwerking (NLP) is een deelgebied van kunstmatige intelligentie dat probeert om natuurlijke taalgegevens te verwerken en te analyseren. Het omvat het leren van machines om met mensen om te gaan in een natuurlijke taal.
De documentatie van Spacy ziet er redelijk goed uit. Eerlijk gezegd. Sommige dingen in de productie zijn echt nutteloos, zoals NLTK. TensorFlow in de tekst is niet erg handig. Ondersteunt talen en dingen die niet worden gevonden. Daarom is het momenteel correct.
Zie video.
Installatie Spacy en configuratie op Mac is heel eenvoudig. Je kan pip gebruiken.
Zorg ervoor dat u de volledige Unicode-versie gebruikt. Wanneer u andere versies gebruikt, kunt u de volgende fouten tegenkomen:: sre_constants.error: bad character range
Je kan het testen met command.
>>> import sys
>>> print(sys.maxunicode)
65535
01. Woorden, zinnen, namen en concepten vinden
Finding words, phrases, names and concepts
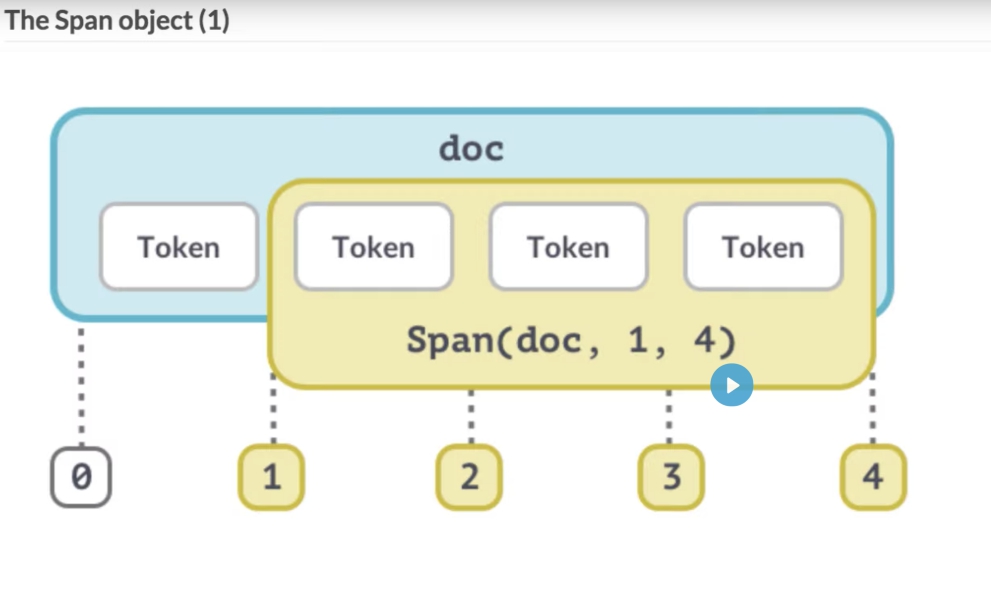
Zo ziet de structuur van doc de mogelijkheid voor span via python slice.
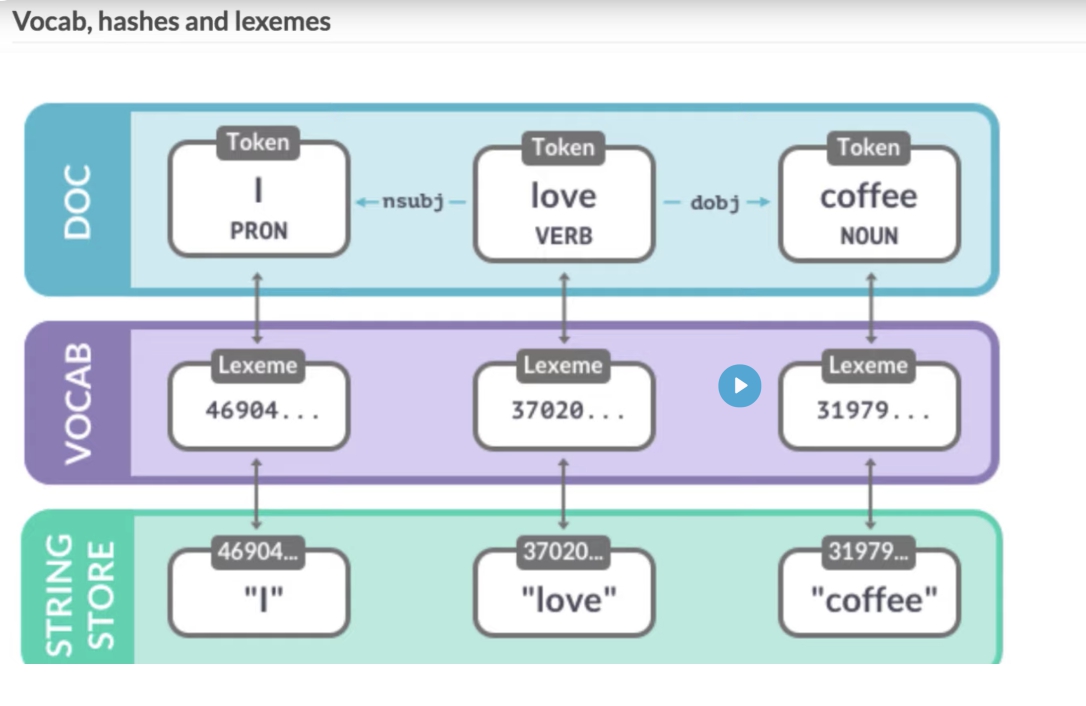
U kunt de belangrijkste objecten die de spaCy API samenstellen in twee categorieën verdelen: containers (zoals Tokens en Doc-objecten) en verwerking pijplijn componenten (zoals de part-of-speech tagger en named entity herkennen).
In dit hoofdstuk worden container objecten verder onderzocht. Door container objecten en hun methoden te gebruiken, hebt u toegang tot de taalkundige annotaties die spaCy aan elk ervan toewijst
token in een tekst.

Token heeft parameters en methods. Index, text ezv.. Zie afbeelding.


In dit voorbeeld gebruikt u de Doc- en Token-objecten van spaCy en lexicale attributen om percentages in een tekst te zoeken. U zoekt twee opeenvolgende tokens: een cijfer en een procentteken.
Gebruik het kenmerk like_num token om te controleren of een token in het document op een getal lijkt.
Haal het token op dat volgt op het huidige token in het document. De index van het volgende token in het document is token.i + 1.
Controleer of het tekstkenmerk van het volgende token een procentteken "%" is.









U kunt nu een van de voorgetrainde modelpakketten van spaCy uitproberen en de voorspellingen in actie zien. Voel je vrij om het uit te proberen op je eigen tekst! Om erachter te komen wat een tag of label betekent, kun je spacy.explain aanroepen in de lus. Bijvoorbeeld: spacy.explain ("PROPN") of spacy.explain ("GPE").
Deel 1 Verwerk de tekst met het nlp-object en maak een doc. Druk voor elk token de token-tekst af, de token's .pos_ (part-of-speech-tag) en de token's .dep_ (afhankelijkheidslabel).

Deel 2
Verwerk de tekst en maak een doc-object.
Herhaal de doc.ents en druk de entiteitstekst en label_attribuut af.

Modellen zijn statistisch en niet altijd juist. Of hun voorspellingen kloppen, hangt af van de trainingsgegevens en de tekst die u verwerkt. Laten we een voorbeeld bekijken.
Verwerk de tekst met het nlp-object.
Herhaal de entiteiten en druk de entiteitstekst en het label af.
Het lijkt erop dat het model 'iPhone X' niet heeft voorspeld. Maak handmatig een reeks voor die token

>>> doc = nlp(u'I want a green apple.') >>> [w for w in doc[4].lefts]
[a, green]

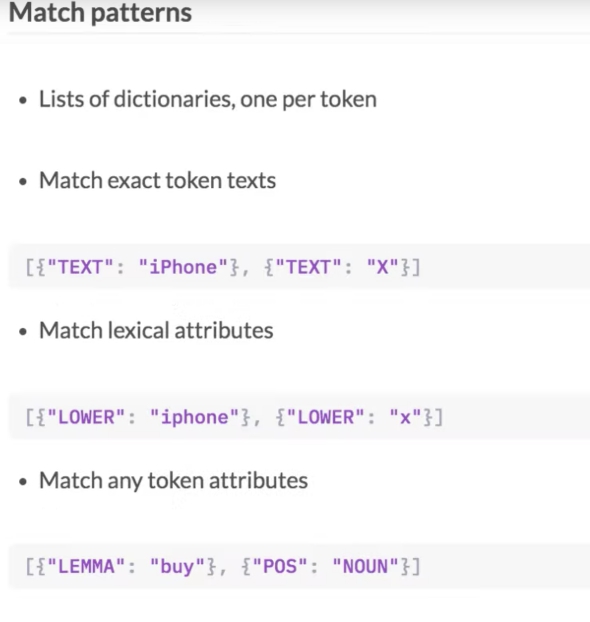


Geavanceerd voorbeeld:


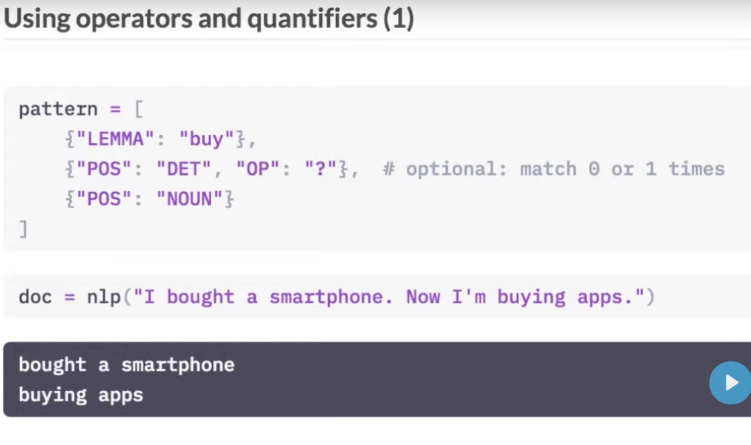

Laten we de regelgebaseerde Matcher van spaCy eens proberen. Je gebruikt het voorbeeld uit de vorige oefening en schrijft een patroon dat overeenkomt met de zin ‘iPhone X’ in de tekst.
Importeer de Matcher vanuit spacy.matcher.
Initialiseer het met de gedeelde vocab van het nlp-object.
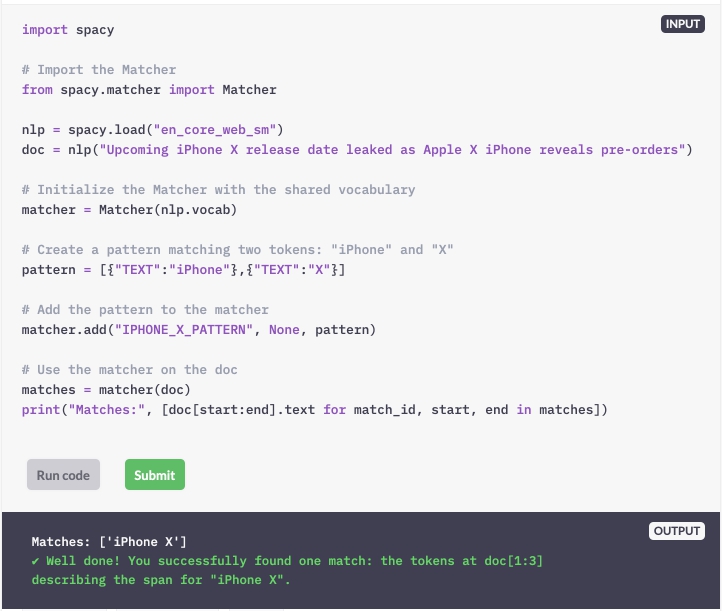
Maak een patroon dat overeenkomt met de "TEXT" -waarden van twee tokens: "iPhone" en "X".
Gebruik de matcher.add-methode om het patroon aan de matcher toe te voegen.
Roep de matcher op het document aan en sla het resultaat op in de variabele matches.
Herhaal de overeenkomsten en verkrijg de overeenkomende reeks van de start- tot de eindindex.
In deze oefening oefen je met het schrijven van complexere overeenkomstpatronen met verschillende tokenattributen en operators.
Deel 1
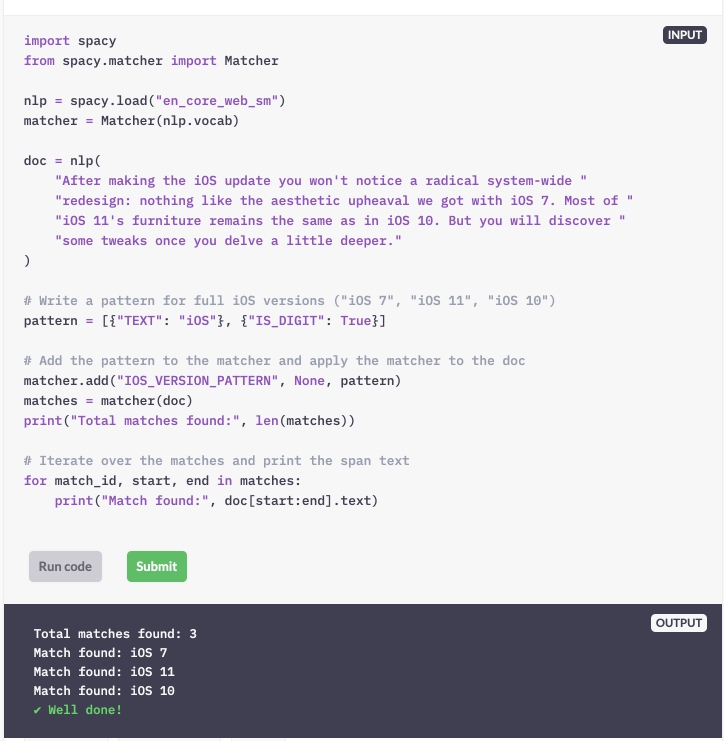
Schrijf een patroon dat alleen overeenkomt met de vermeldingen van de volledige iOS-versies: "iOS 7", "iOS 11" en "iOS 10".
Deel 2
Schrijf een patroon dat alleen overeenkomt met vormen van "download" (tokens met het lemma "download"), gevolgd door een token met de deeltje-tag "PROPN" (eigennaam).

Deel 3
Schrijf een patroon dat overeenkomt met bijvoeglijke naamwoorden ("ADJ") gevolgd door een of twee "NOUN" -en (een zelfstandig naamwoord en een optioneel zelfstandig naamwoord).
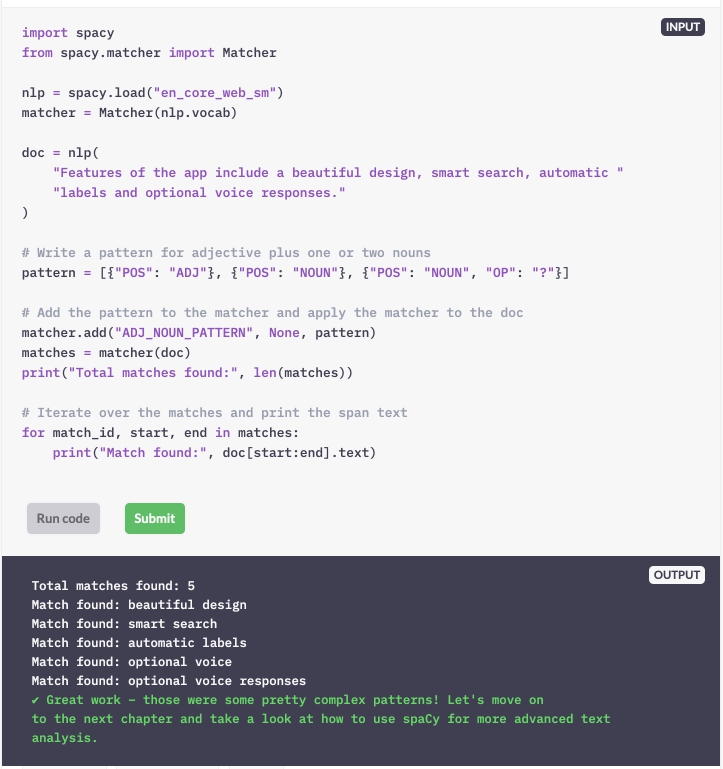
Hoofdstuk 2: Grootschalige data-analyse met spaCy
In dit hoofdstuk gebruik je je nieuwe vaardigheden om specifieke informatie uit grote tekstvolumes te halen. U leert hoe u optimaal gebruik kunt maken van de datastructuren van spaCy, en hoe u statistische en regelgebaseerde benaderingen voor tekstanalyse effectief kunt combineren.



Deel 1 Zoek de string “cat” op in nlp.vocab.strings om de hash te krijgen.
Zoek de hash op om de string terug te krijgen.

Deel 2
Zoek het stringlabel "PERSON" op in nlp.vocab.strings om de hash te krijgen.
Zoek de hash op om de string terug te krijgen.





Laten we vanaf het begin enkele Doc-objecten maken!
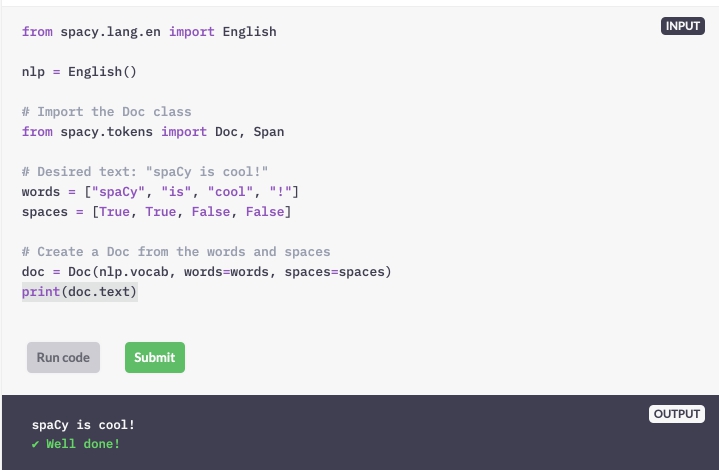
Deel 1
Importeer het document van spacy.tokens.
Maak een document van de woorden en spaties. Vergeet niet de woordenschat door te geven!

Installatie op echte server Ubuntu verwachten functies unicode in plaats van string.
Dat is dus tijdens verwerking gemerkt. Er zou dus eerste conversie moeten gebeuren naar unicode.


Deel 2
Importeer het document van spacy.tokens.
Maak een document van de woorden en spaties. Vergeet niet de woordenschat door te geven!

In deze oefening maakt u de Doc- en Span-objecten handmatig en werkt u de benoemde entiteiten bij, net zoals spaCy dat achter de schermen doet. Er is al een gedeeld nlp-object gemaakt.
Importeer de Doc- en Span-klassen vanuit spacy.tokens.
Gebruik de Doc-klasse rechtstreeks om een document te maken van de woorden en spaties.
Maak een span voor "David Bowie" vanuit het document en geef het het label "PERSON".
Overschrijf de doc.ents met een lijst van één entiteit, de "David Bowie" reeks.

De code in dit voorbeeld probeert een tekst te analyseren en alle eigennamen te verzamelen die worden gevolgd door een werkwoord.

Herschrijf de code om de native token-attributen te gebruiken in plaats van lijsten met token_texts en pos_tags.
Loop over elk token in het document en controleer het token.pos_ attribuut.
Gebruik doc [token.i + 1] om te zoeken naar het volgende token en zijn .pos_attribuut.
Als een eigennaam vóór een werkwoord wordt gevonden, drukt u het token. Tekst af.


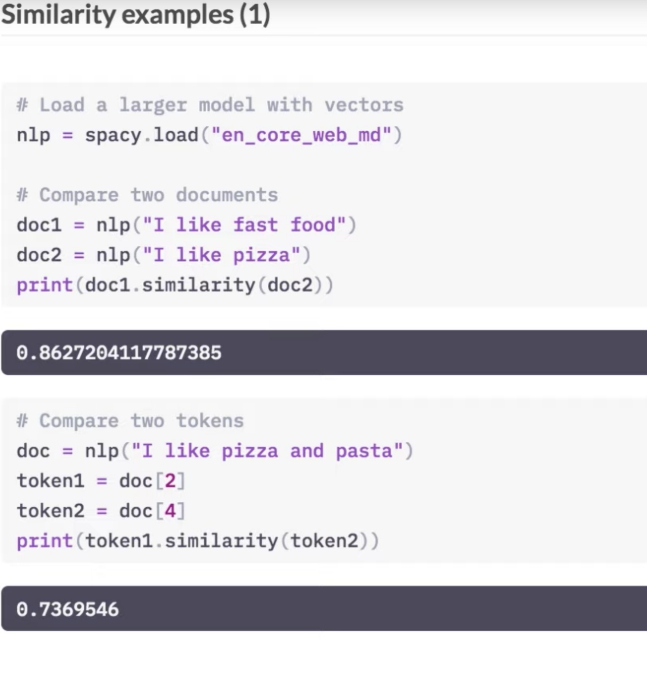



In deze oefening gebruik je een groter Engels model, dat ongeveer 20.000 woordvectoren bevat. Het model is al voorgeïnstalleerd.
Laad het medium "en_core_web_md" -model met woordvectoren.
Druk de vector voor "bananen" af met het kenmerk token.vector.

In deze oefening gebruikt u de gelijkenismethoden van spaCy om Doc-, Token- en Span-objecten te vergelijken en gelijkwaardigheidsscores te krijgen.
Deel 1
Gebruik de doc.similarity-methode om doc1 met doc2 te vergelijken en het resultaat af te drukken.

Deel 2
Gebruik de methode token.similarity om token1 met token2 te vergelijken en het resultaat af te drukken.

Deel 3
Creëer overspanningen voor "geweldig restaurant" / "echt leuke bar".
Gebruik span.similarity om ze te vergelijken en het resultaat af te drukken.








Beide patronen in deze oefening bevatten fouten en komen niet overeen zoals verwacht. Kunt u ze repareren? Als je vastloopt, probeer dan de tokens in het document af te drukken om te zien hoe de tekst wordt gesplitst en pas het patroon aan zodat elk woordenboek één token vertegenwoordigt.
Bewerk patroon1 zodat het correct overeenkomt met alle hoofdletterongevoelige vermeldingen van "Amazon" plus een eigennaam in hoofdletters en kleine letters.
Bewerk pattern2 zodat het correct overeenkomt met alle hoofdletterongevoelige vermeldingen van "ad-free", plus het volgende zelfstandig naamwoord.


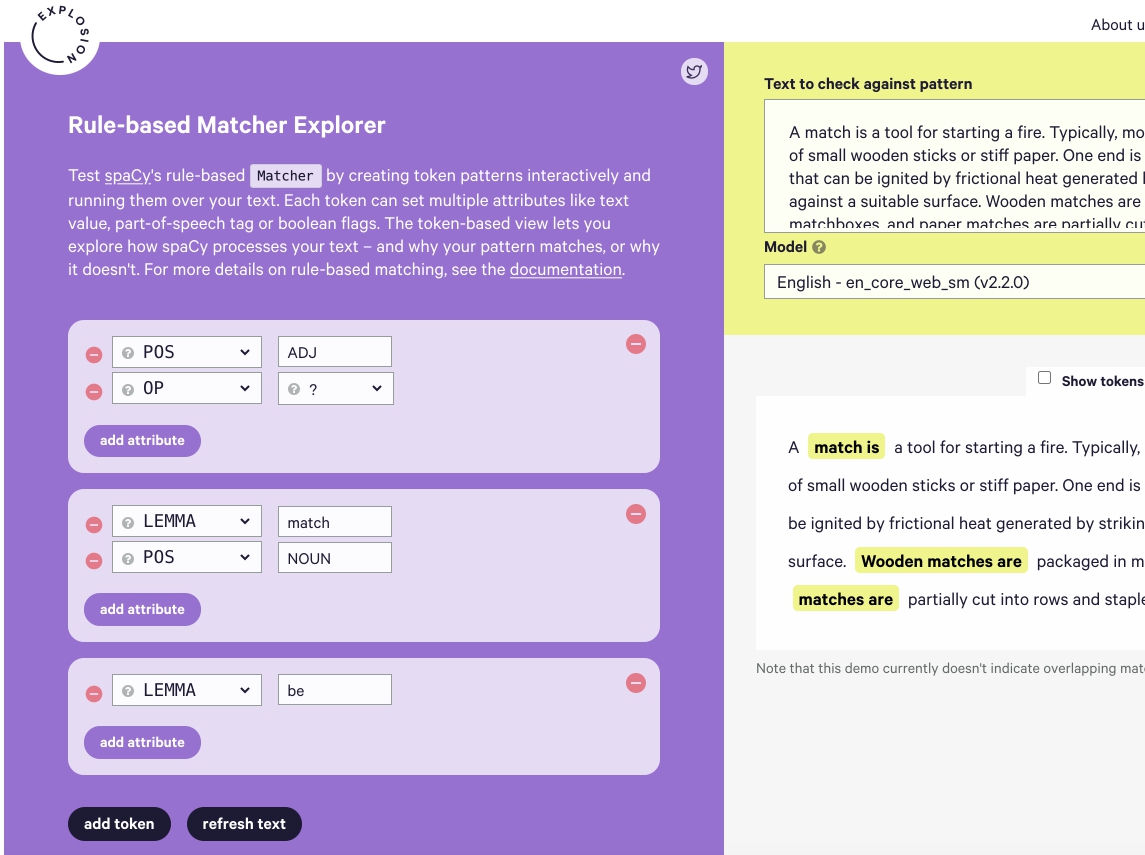
Hier is belangrijk te begrijpen welke Attributes zijn er al in Matcher object.
Om te testen is er een interesante tool.
https://explosion.ai/demos/matcher
https://spacy.io/api/annotation
https://spacy.io/usage/rule-based-matching#matcher
Soms is het efficiënter om exacte strings te matchen in plaats van patronen te schrijven die de individuele tokens beschrijven. Dit geldt vooral voor eindige categorieën dingen - zoals alle landen van de wereld. We hebben al een lijst met landen, dus laten we deze gebruiken als basis voor ons script voor informatie-extractie. Een lijst met stringnamen is beschikbaar als de variabele COUNTRIES.
Importeer de PhraseMatcher en initialiseer deze met het gedeelde vocab als de variabele matcher.
Voeg de zinpatronen toe en roep de matcher op het document aan.

In de vorige oefening heb je een script geschreven met spaCy's PhraseMatcher om landnamen in tekst te vinden. Laten we die landovereenkomst gebruiken voor een langere tekst, de syntaxis analyseren en de entiteiten van het document bijwerken met de overeenkomende landen.
Herhaal de overeenkomsten en maak een Span met het label "GPE" (geopolitieke entiteit).
Overschrijf de entiteiten in doc.ents en voeg de overeenkomende reeks toe.
Verkrijg het roothead-token van de overeenkomende span.
Druk de tekst van het hoofdfiche en de spanwijdte af.


Dan leer je over de tekstverwerkingspijplijn, een reeks basis NLP-bewerkingen die je zult gebruiken om de betekenis en bedoeling van een discours te bepalen. Deze bewerkingen omvatten tokenisatie, lemmatisering, tagging van spraakgedeelten, parsing van syntactische afhankelijkheden en herkenning van benoemde entiteiten.


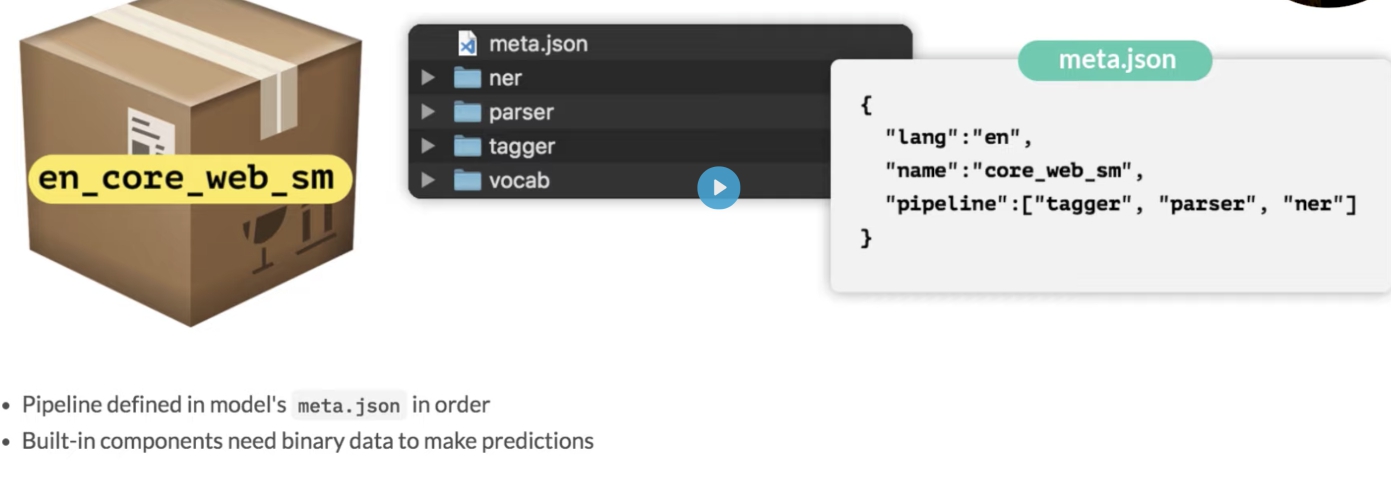


Pijplijncomponenten uitschakelen
spaCy stelt u in staat om een geselecteerde set pijplijncomponenten te laden, waardoor de componenten die niet nodig zijn, worden uitgeschakeld. U kunt dit doen bij het maken van een nlp-object door de parameter disable in te stellen:
nlp = spacy.load('en', disable=['parser'])
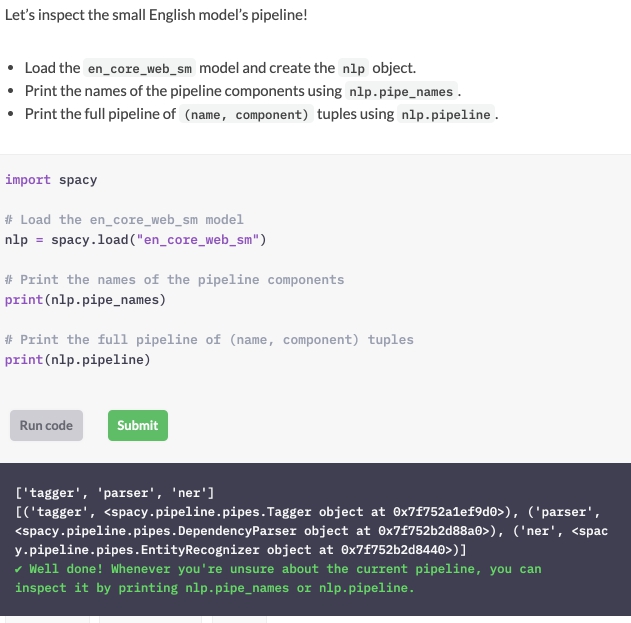
Laten we de pijplijn van het kleine Engelse model eens bekijken!
Laad het en_core_web_sm-model en maak het nlp-object.
Druk de namen van de pijplijncomponenten af met nlp.pipe_names.
Druk de volledige pipeline van (naam, component) tuples af met nlp.pipeline.





Het voorbeeld toont een gebruikerscomponent die het aantal tokens in een document afdrukt. Kunt u het afmaken?
Voltooi de componentfunctie met de lengte van het document.
Voeg de length_component toe aan de bestaande pijplijn als de eerste component.
Probeer de nieuwe pijplijn uit en verwerk alle tekst met het nlp-object - bijvoorbeeld "Dit is een zin."

In deze oefening ga je een gebruikerscomponent schrijven die de PhraseMatcher gebruikt om dierennamen in het document te zoeken en de overeenkomende reeksen aan de doc.ents toevoegt. Er is al een PhraseMatcher met de dierenpatronen gemaakt als variabele matcher.
Definieer de gebruikerscomponent en pas de matcher toe op het document.
Maak een span voor elke overeenkomst, wijs de label-ID toe voor "ANIMAL" en overschrijf de documenten met de nieuwe reeksen.
Voeg de nieuwe component toe aan de pijplijn na de component "ner".
Verwerk de tekst en druk de entiteitstekst en het entiteitslabel af voor de entiteiten in doc.ents.

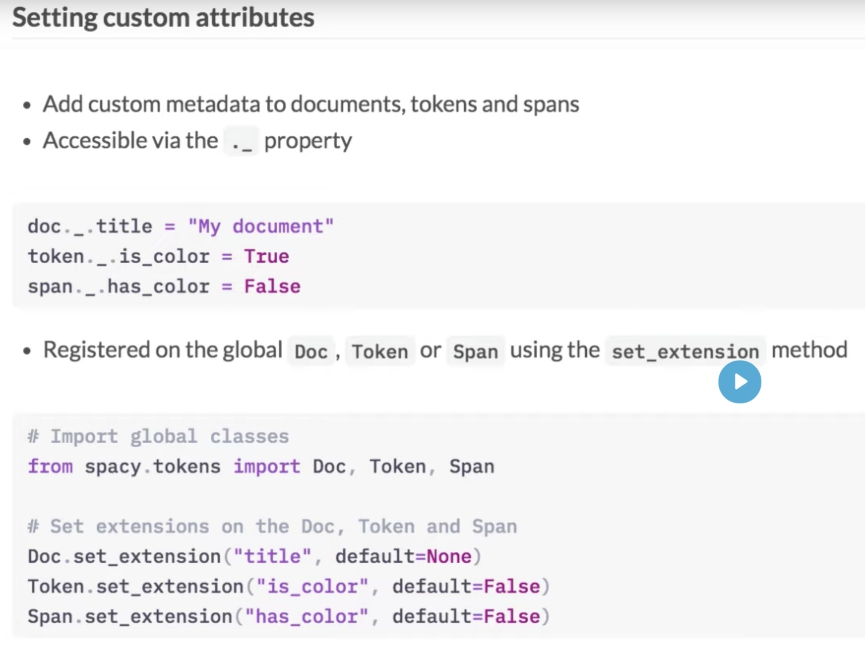


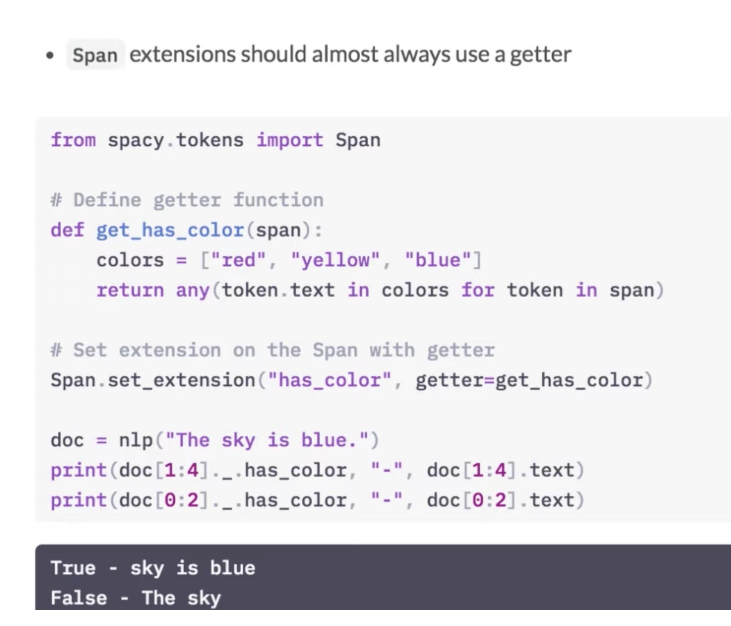

Laten we eens oefenen met het instellen van enkele extensiekenmerken.
Stap 1
Gebruik Token.set_extension om "is_country" te registreren (standaard False).
Werk het bij voor "Spanje" en druk het af voor alle tokens.

Op deze manier kan men een extensie schrijven die zal zeggen of een token zoals nummer in de document te vinden is. Bijvoorbeeld: vijf..


In deze oefening combineert u aangepaste extensiekenmerken met de voorspellingen van het model en maakt u een kenmerk-getter die een Wikipedia-zoek-URL retourneert als de reeks een persoon, organisatie of locatie is.
Vul de get_wikipedia_url getter in zodat deze alleen de URL retourneert als het label van de span in de lijst met labels staat.
Stel de Span-extensie "wikipedia_url" in met de getter get_wikipedia_url.
Herhaal de entiteiten in het document en voer hun Wikipedia-URL uit.

Extensiekenmerken zijn vooral krachtig als ze worden gecombineerd met aangepaste pijplijncomponenten. In deze oefening schrijft u een pijplijncomponent die landnamen vindt en een aangepast extensiekenmerk dat de hoofdstad van een land retourneert, indien beschikbaar.
Een zoekwoordcombinatie met alle landen is beschikbaar als variabele matcher. Een woordenboek van landen die zijn toegewezen aan hun hoofdsteden is beschikbaar als de variabele CAPITALS.
Vul de landen_component in en maak een Span met het label "GPE" (geopolitieke entiteit) voor alle overeenkomsten.
Voeg de component toe aan de pijplijn.
Registreer het Span-extensiekenmerk "capital" met de getter get_capital.
Verwerk de tekst en druk de entiteitstekst, entiteitslabel en entiteitskapitaal af voor elke entiteitsbereik in doc.ents.
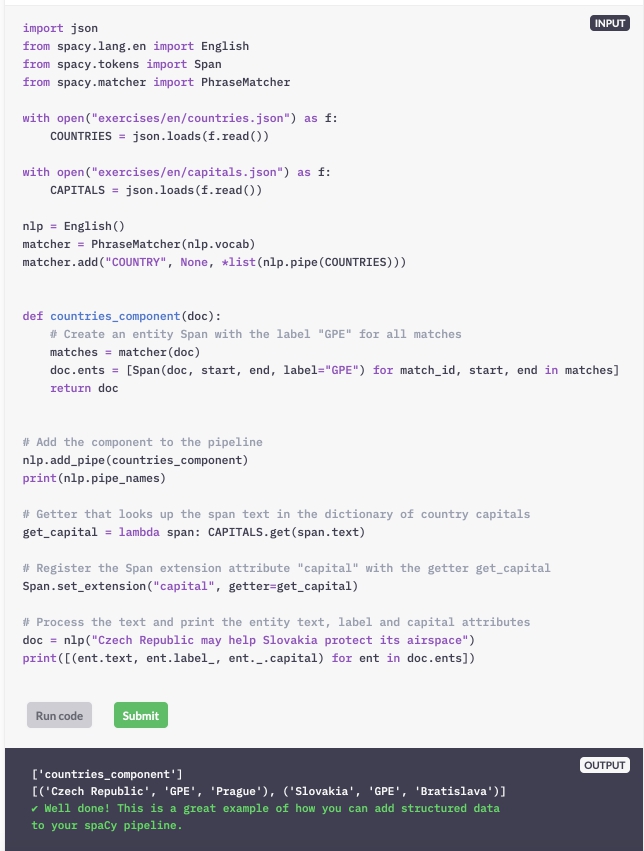




Deze als je alleen in tokens zou graag verdelen en dan zelf zonder pipline verwerken. Of je kan apart een of meerdere componenten uitschakelen.

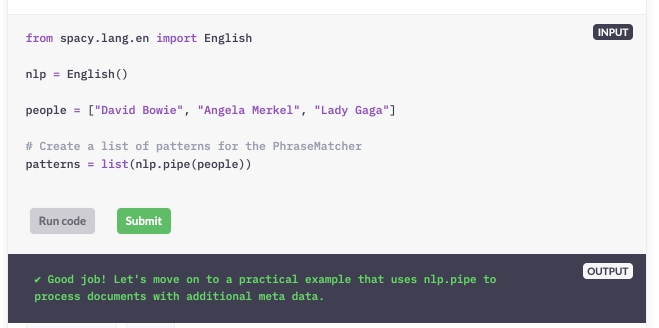
In deze oefening gebruik je nlp.pipe voor efficiëntere tekstverwerking. Het nlp-object is al voor u aangemaakt. Een lijst met tweets over een populaire Amerikaanse fastfoodketen is beschikbaar als de variabele TEXTS.
Deel 1
Herschrijf het voorbeeld om nlp.pipe te gebruiken. In plaats van de teksten te herhalen en ze te verwerken, herhaal je de doc-objecten die door nlp.pipe worden opgeleverd.

Deel 2
Herschrijf het voorbeeld om nlp.pipe te gebruiken. Vergeet niet de lijst () rond het resultaat te bellen om er een lijst van te maken.

Deel 3
Herschrijf het voorbeeld om nlp.pipe te gebruiken. Vergeet niet de lijst () rond het resultaat te bellen om er een lijst van te maken.
Deel 2
Schakel de tagger en parser uit met de methode nlp.disable_pipes.
Verwerk de tekst en druk alle entiteiten in het document af.

In deze oefening gebruik je aangepaste attributen om meta-informatie van de auteur en het boek aan citaten toe te voegen.
Een lijst met [tekst, context] voorbeelden is beschikbaar als de variabele DATA. De teksten zijn citaten uit beroemde boeken en de contextenwoordenboeken met de sleutels "auteur" en "boek".
Gebruik de set_extension-methode om de aangepaste attributen "auteur" en "boek" in het document te registreren, die standaard op Geen staan.
Verwerk de [text, context] -paren in DATA met nlp.pipe met as_tuples = True.
Overschrijf de doc._.book en doc._.author met de respectievelijke info die is doorgegeven als de context.

In dit hoofdstuk leert u hoe u de statistische modellen van spaCy kunt bijwerken om ze aan te passen aan uw situatie - bijvoorbeeld om een nieuw type entiteit in online commentaren te voorspellen. Je schrijft vanaf het begin je eigen trainingslus en begrijpt de basisprincipes van hoe training werkt, samen met tips en trucs die je eigen NLP-projecten succesvoller kunnen maken.






Schrijf een patroon voor twee tokens waarvan de kleine letters overeenkomen met "iphone" en "x".
Schrijf een patroon voor twee tokens: één token waarvan de kleine letters overeenkomen met "iphone" en een cijfer.
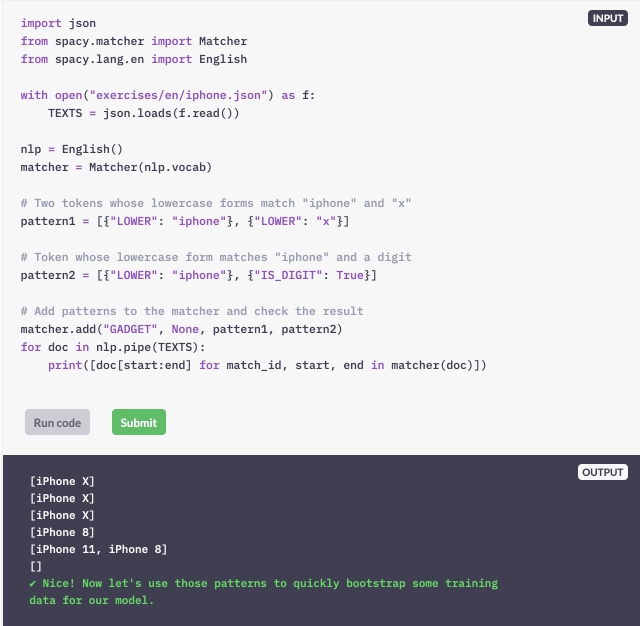
Laten we de wedstrijdpatronen gebruiken die we in de vorige oefening hebben gemaakt om een reeks trainingsvoorbeelden op te starten. Een lijst met zinnen is beschikbaar als de variabele TEXTS.
Maak een doc-object voor elke tekst met nlp.pipe.
Match op het document en maak een lijst met overeenkomende bereiken.
Krijg (startkarakter, eindkarakter, label) tuples van overeenkomende reeksen.
Formatteer elk voorbeeld als een tupel van de tekst en een dictaat, waarbij "entiteiten" worden toegewezen aan de entiteitstupels.
Voeg het voorbeeld toe aan TRAINING_DATA en bekijk de afgedrukte gegevens.






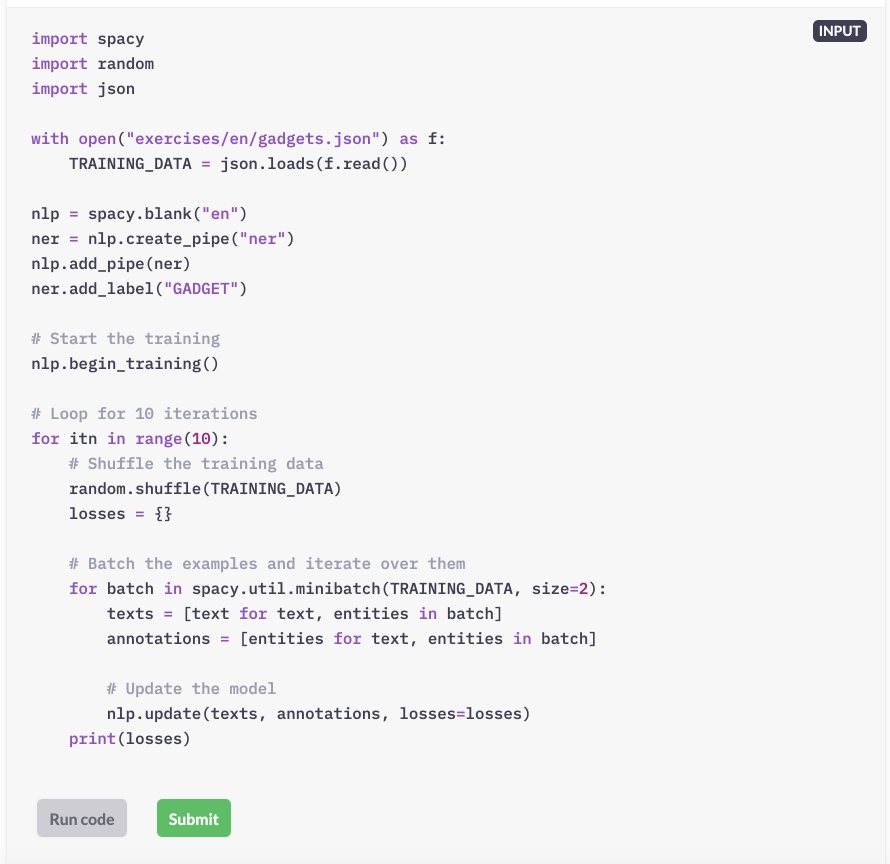
In deze oefening bereid je een spaCy-pijplijn voor om de entiteitsherkenner te trainen om "GADGET" -entiteiten in een tekst te herkennen, bijvoorbeeld "iPhone X".
Maak een leeg "en" -model, bijvoorbeeld met behulp van de methode spacy.blank.
Maak een nieuwe entiteitsherkenner met nlp.create_pipe en voeg deze toe aan de pijplijn.
Voeg het nieuwe label "GADGET" toe aan de entiteitsherkenner met behulp van de add_label-methode op de pijplijncomponent.

Laten we vanaf nul een eenvoudige trainingslus schrijven!
De pijplijn die u in de vorige oefening heeft gemaakt, is beschikbaar als het nlp-object. Het bevat al de entiteitsherkenner met het toegevoegde label "GADGET".
De kleine reeks gelabelde voorbeelden die u eerder heeft gemaakt, is beschikbaar als TRAINING_DATA. Om de voorbeelden te zien, kunt u ze in uw script afdrukken.
Roep nlp.begin_training aan, maak een trainingslus voor 10 iteraties en schud de trainingsgegevens door elkaar.
Maak batches met trainingsgegevens met behulp van spacy.util.minibatch en herhaal de batches.
Converteer de (tekst, annotaties) tupels in de batch naar lijsten met teksten en annotaties.
Gebruik voor elke batch nlp.update om het model bij te werken met de teksten en annotaties.

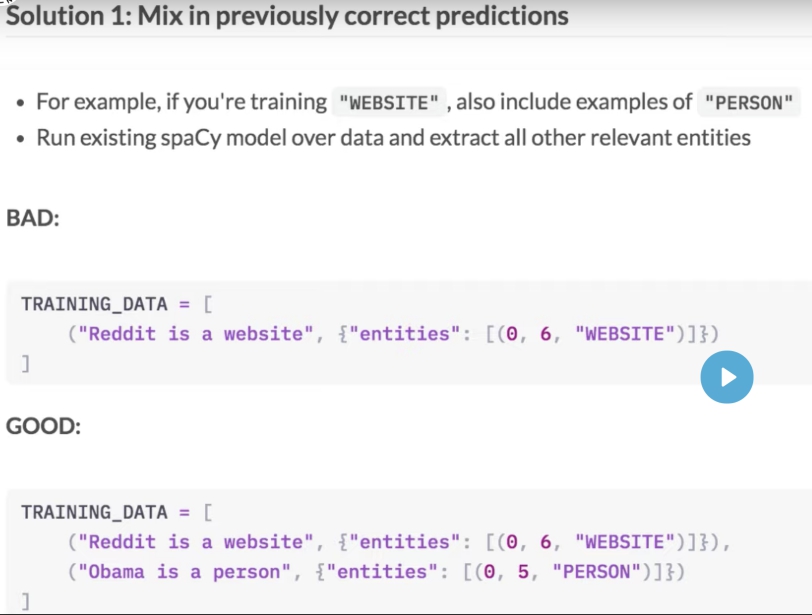




Hier is een klein voorbeeld van een dataset die is gemaakt om een nieuw entiteitstype 'WEBSITE' te trainen. De originele dataset bevat een paar duizend zinnen. In deze oefening doe je de labels met de hand. In het echte leven wil je dit waarschijnlijk automatiseren en een annotatietool gebruiken - bijvoorbeeld Brat, een populaire open-sourceoplossing, of Prodigy, onze eigen annotatietool die integreert met spaCy.
Deel 1
Voltooi de entiteitscorrecties voor de "WEBSITE" -entiteiten in de gegevens. Voel je vrij om len () te gebruiken als je de karakters niet wilt tellen.
Eind oefeningen. Verder zie Nota's van boek NATURAL LANGUAGE PROCESSING WITH PYTHON AND SPACY by Yuli Vasiliev. No starch press San Francisco.
https://prodi.gy/
http://brat.nlplab.org/




https://spacy.io/usage/examples#textcat
Interessante attributen / propertjes van doc
>>> doc = nlp(u'I want a green apple.') >>> [w for w in doc[4].lefts]
[a, green]
doc.sents
for sent in doc.sents
[sent[i] for i in range(len(sent))]
doc.noun_chunks
>>> doc = nlp(u'A noun chunk is a phrase that has a noun as its head.') >>> for chunk in doc.noun_chunks:
... print(chunk)
span.merge
>>> span = doc[1:4]
>>> lem_id = doc.vocab.strings[span.text] >>> span.merge(lemma = lem_id)
Golden Gate Bridge
Replace componet met eigen getreinde
optimizer = nlp.entity.create_optimizer() import random
for i in range(25): random.shuffle(TRAIN_DATA)
for text, annotations in TRAIN_DATA:
nlp.update([text], [annotations], sgd=optimize)
ner.to_disk('/usr/to/ner)
>>> import spacy
>>> from spacy.pipeline import EntityRecognizer
>>> nlp = spacy.load('en', disable=['ner']) v
>>> ner = EntityRecognizer(nlp.vocab)
>>> ner.from_disk('/usr/to/ner)
>>> nlp.add_pipe(ner)
Categorisering
Interesante links
https://github.com/explosion/spacy-transformers
https://github.com/huggingface/transformers
State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0
https://nightly.spacy.io/usage/linguistic-features
GUIDES: Linguistic Features, Rule-based Matching, Processing Pipelines, Embeddings & Transformers ...
http://brat.nlplab.org/
brat rapid annotation tool
https://prodi.gy/
Radically efficient machine teaching.
An annotation tool powered
by active learning.
https://explosion.ai/demos/displacy/
The displaCy dependency visualizer generates a syntactic dependency visualization for a submitted text.
Comments
Post a Comment