
Combining Firebase with other servers like Elasticsearch, a crawler, or a mailing server on separate hardware can be a highly intriguing approach. Such integrations have the potential to greatly enhance development and automation processes, resulting in significant effectiveness.
In this example, we utilize Python to establish the necessary connection.
sudo pip install firebase-admin
import firebase_admin
from firebase_admin import credentials
cred = credentials.Certificate("path/to/serviceAccountKey.json")
firebase_admin.initialize_app(cred)
After creating a Firebase project, you can easily initialize the SDK by utilizing Google Application Default Credentials. This approach is highly recommended for applications operating in Google environments like Cloud Run, App Engine, and Cloud Functions because the default credentials lookup is automated. No additional configuration or environment variables are required.
To customize initialization options for services like Realtime Database, Cloud Storage, or Cloud Functions, you can utilize the FIREBASE_CONFIG environment variable. If the content of the FIREBASE_CONFIG variable starts with a {, it will be interpreted as a JSON object. Alternatively, if the string represents a file path, the SDK will assume it contains the necessary options in a JSON format.
https://firebase.google.com/docs/admin/setup#python
Download and install AccountKey.json
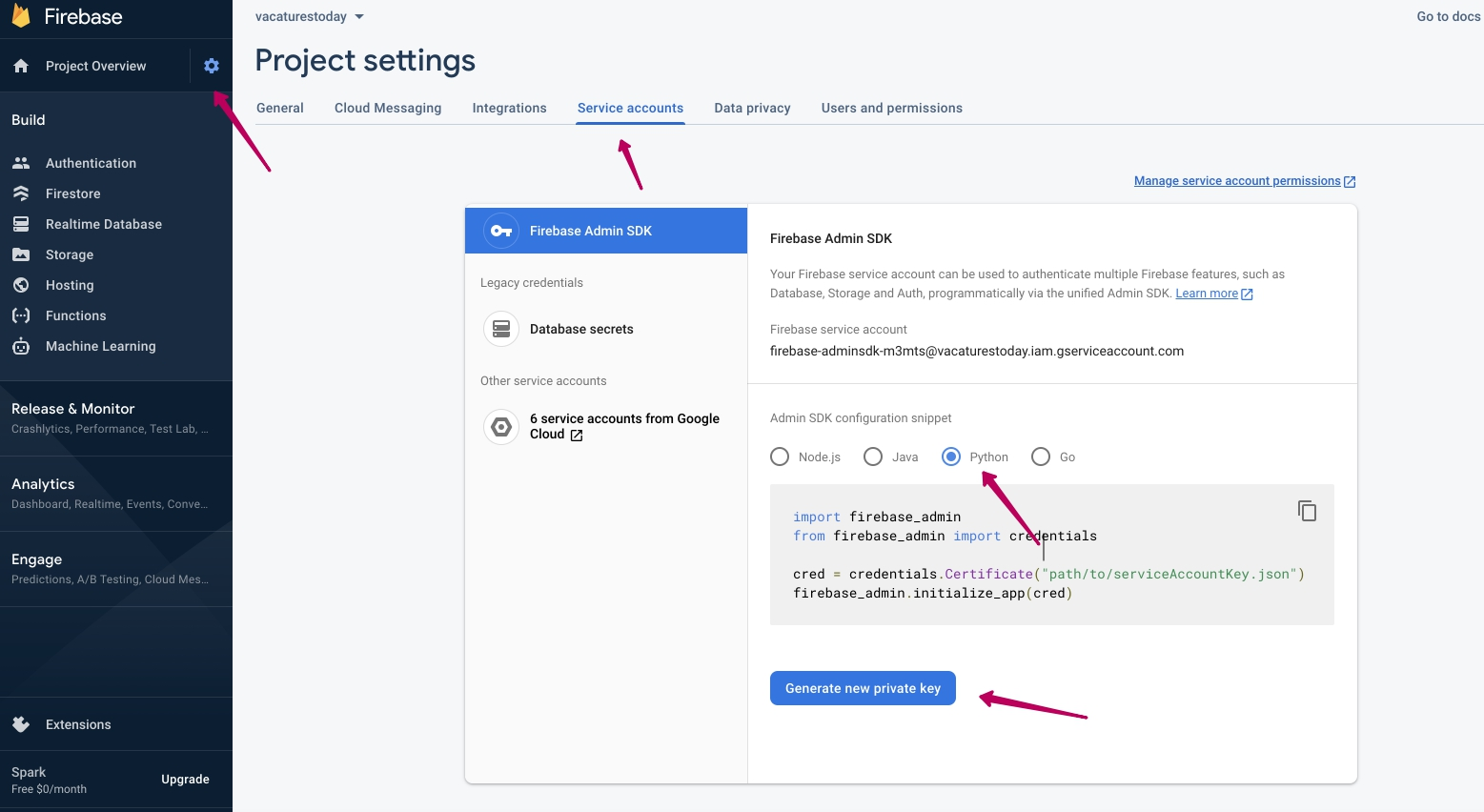
Usage example
Static for firebase
https://bitbucket.org/onlinesolutionsgroup/vacatures.today/src/master/categories_from_firestore_generator.py
Django XML sync
https://bitbucket.org/onlinesolutionsgroup/vacaturestoday/src/master/
Script example: Select jobs from database via ORM and push it to Firebase
https://bitbucket.org/onlinesolutionsgroup/vacaturestoday/src/master/job/management/commands/syncfirebaseCloudFirestore.py
Init and Retrieve Data from
https://firebase.google.com/docs/database/admin/start
https://firebase.google.com/docs/database/admin/retrieve-data

def handle(self, *args, **options):
cred = credentials.Certificate("/")
firebase_admin.initialize_app(cred, {
'databaseURL': 'https://database.firebaseio.com'
})
jobs = Job.objects.all()[:3]
ref = db.reference("/jobs")
import pdb;pdb.set_trace()
for job in jobs:
json = self.create_json(job)
ref.push(json)
def create_json(self, job):
json = {
"id": job.source_unique,
"company_name": self.clean_json_value(job.company_name),
"description": self.clean_json_value(job.description),
"url": self.clean_json_value(job.url),
"title": self.clean_json_value(job.title),
"city": self.clean_json_value(job.city),
"zip_code": self.clean_json_value(job.zip_code)
}
return json
snapshot = ref.order_by_child('id').equal_to().get()
If you get an error something like this.
firebase_admin.exceptions.InvalidArgumentError: Index not defined, add ".indexOn": "id", for path "/jobs", to the rules
https://firebase.google.com/docs/database/security/indexing-data
Add index in your database rules

for job in jobs:
json = self.create_json(job)
snapshot = ref.order_by_child('id').equal_to(job.source_unique).get()
if not snapshot:
ref.push(json)
Example read data via Javascript
var firebaseConfig = { .... }
firebase.initializeApp(firebaseConfig);
var db = firebase.database();
var ref = db.ref("jobs");
ref.orderByChild("id").equalTo(job_id).on("value", function(snapshot) {
obj = snapshot.val();
window.location = obj[Object.keys(obj)[0]]["url"];
//console.log(snapshot.val());
});
var ref2 = db.ref("jobs/-MWEL0phaE5glY_PjsPa/url");
ref2.on('value', (snapshot) => {
data = snapshot.val();
console.log(data);
});
Cloud Firestore
If database is efficient with object handling and frequent updates then Firestore is effective for complicated queries. Here is very good document about difference.
https://firebase.google.com/docs/database/rtdb-vs-firestore
Connection and authentication is the same as by Realtime Database but there are three layers to our connection.
Database > Collection > Document
from firebase_admin import credentials, firestore
db = firestore.client() # this connects to our Firestore database
collection = db.collection(‘jobs’) # opens 'places' collection
doc = collection.document(‘python-developer’) # specifies the 'rome' document

Each layer has its own set of methods that enable us to perform different operations at the database, collection, or document level.
We use the get method to retrieve data. Let's use this method to get pythondeloper documentation:
doc = collection.document(‘python-developer’)
res = doc.get().to_dict()
print(res)
When collecting, we can also perform a .get() operation to return an array of all documents contained in it. If we have two documents, it will look like this:

To select advanced queries or quick test you can use this tool.

Add documents from the django query set.
jobs = Job.objects.filter(for_index=False)
for job in jobs:
json = self.create_json(job)
if not collection.document(job.source_unique).get().exists:
res = collection.document(job.source_unique).set(json)
print(res)
Delete by key.
for job in offline_jobs:
print("Delete:" + str(job.source_unique))
collection.document(job.source_unique).delete()
https://firebase.google.com/docs/firestore/query-data/queries
python
firebase_admin.initialize_app(cred)
db = firestore.client()
jobs = db.collection("jobs")
jobs.where(u"category", u"==", category)
jobs = self.convert_to_dict(jobs.get())
Very important use unicode in WHERE and stream if it collection filter

Get started with Cloud Firestore Security Rules
https://firebase.google.com/docs/firestore/security/get-started
Use Shell to test your Rules

Simple Example Rules
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /clicks/{document=**} {
allow write: if true;
allow read: if false;
}
match /jobs/{document=**} {
allow write: if false;
allow read: if true;
}
match /{document=**} {
allow read, write: if false;
}
}
}
Why use Cloudflare with Firebase?
- Security & Protection
- Cost Savings & Prevention
- Speed
If you save timestamps you can get all the information from logs. Like IP, User agent etc..
Realtime Database
Example script in vacatures today brance.spontaneousmail/management/commands/unsubscribe_firebaseform.py
class Command(BaseCommand):
"""
Unsubscriebe emails from firebase database
"""
def handle(self, *args, **options):
"""
"""
firebase = pyrebase.initialize_app(config)
db = firebase.database()
contacts = db.child("unsubscribe").get()
#import pdb;pdb.set_trace()
for contact in contacts.each():
self.unsubsribe_emails(contact.val())
def unsubsribe_emails(self, item):
#import pdb;pdb.set_trace()
try:
term = item['email'].strip().lower()
print(term)
utils.unsubscribe(term, "Unsubscribe form")
except:
traceback.print_exc(file=sys.stdout)
Config
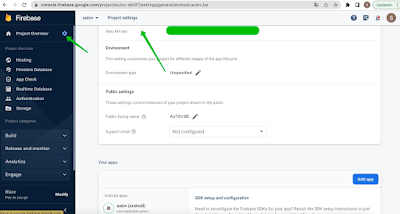

The information to configure connection can be found in setting and download two files there.

And

You may need to create an app if it hasn't been created yet.
Another example of connection can be done via admin SDK. See en example here.
https://firebase.google.com/docs/database/admin/start
Then if data only needs to be done 1 time then easy way is export as json and then file system parsing.
Code example:
import firebase_admin
from firebase_admin import credentials
from firebase_admin import db
# Fetch the service account key JSON file contents
cred = credentials.Certificate('path/to/serviceAccountKey.json')
# Initialize the app with a service account, granting admin privileges
firebase_admin.initialize_app(cred, {
'databaseURL': 'https://databaseName.firebaseio.com'
})
# As an admin, the app has access to read and write all data, regradless of Security Rules
ref = db.reference('restricted_access/secret_document')
print(ref.get())
So, what you get with code like this.
(Pdb) dir(offers)
['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
(Pdb) type(offers)
<class 'dict'>
class Command(BaseCommand):
db = None
def handle(self, *args, **options):
cred = credentials.Certificate("/home/auto-verkopen-belgie-firebase-adminsdk-p87c9-2d017ed08a.json")
firebase_admin.initialize_app(cred, {
'databaseURL': 'https://auto-verkopen-belgie.firebaseio.com'
})
ref = db.reference('/offers')
offers = ref.get()
import pdb; pdb.set_trace()
So, dic operations are working on this "offers" object.
J-2INOtvaBGjRQ', '-NX63X_JGCtjVX0G6L64', '-NXAu3AN8Y8dKj8wCkRL', '-NXDW_qiIeBIv-RdtDPD', '-NXFgmCz9joFbMX5hNwX', '-NXGHJt8ECTiF40-cfqN', '-NXJkf4S_W-7LzNos_PO', '-NXLi5-DF3gkNLk2WUI3', '-NXOiSguDOFMMs7mKuDT', '-NXP2RWFg7jjblIkAm0n', '-NXPpghWaKF2btLCfcRr', '-NXQi_-pza96-mWTihyx', '-NXTaAAZZUJlnvVIMpqv'])
(Pdb) print(offers.keys())
Comments
Post a Comment