Often it happens in the morning that you get up and then you see that your site is about 2-3 hours offline.
If you see some message like..
OperationalError at file_name
ERROR: all backend nodes are down, pgpool requires at least one valid node
HINT: repair the backend nodes and restart pgpool
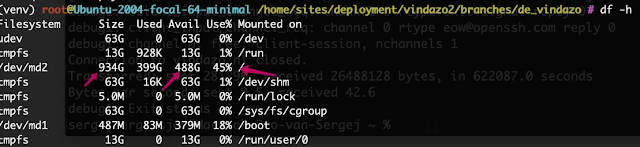
You have to check df -h and see of space on hardrive is full.
Or you can use
Ncdu
This is a very good command to find hard drive problems.
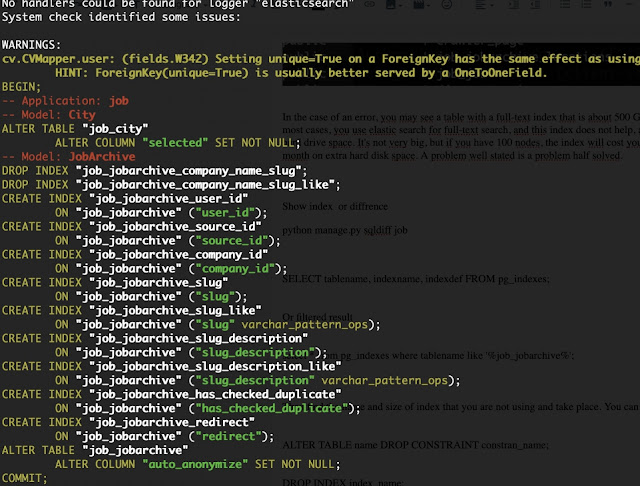
First check that you are /var/logs. Sometimes this is caused by you forgetting the debugger in verbose mode. And you are running a hard drive full of logs. But in this case, we will check for more difficulties. I will write some design decisions to delete some unused indexes, but these indexes are automatically for very large database tables with about 25 million records and more.
SELECT pg_size_pretty( pg_database_size(“db_name”) );
894GB
Show tables
\dt
Shows supper full output sorted by table and index size
WITH RECURSIVE pg_inherit(inhrelid, inhparent) AS
(select inhrelid, inhparent
FROM pg_inherits
UNION
SELECT child.inhrelid, parent.inhparent
FROM pg_inherit child, pg_inherits parent
WHERE child.inhparent = parent.inhrelid),
pg_inherit_short AS (SELECT * FROM pg_inherit WHERE inhparent NOT IN (SELECT inhrelid FROM pg_inherit))
SELECT table_schema
, TABLE_NAME
, row_estimate
, pg_size_pretty(total_bytes) AS total
, pg_size_pretty(index_bytes) AS INDEX
, pg_size_pretty(toast_bytes) AS toast
, pg_size_pretty(table_bytes) AS TABLE
FROM (SELECT *, total_bytes-index_bytes-COALESCE(toast_bytes,0) AS table_bytes
FROM ( SELECT c.oid
, nspname AS table_schema
, relname AS TABLE_NAME
, SUM(c.reltuples) OVER (partition BY parent) AS row_estimate
, SUM(pg_total_relation_size(c.oid)) OVER (partition BY parent) AS total_bytes
, SUM(pg_indexes_size(c.oid)) OVER (partition BY parent) AS index_bytes
, SUM(pg_total_relation_size(reltoastrelid)) OVER (partition BY parent) AS toast_bytes
, parent
FROM (
SELECT pg_class.oid
, reltuples
, relname
, relnamespace
, pg_class.reltoastrelid
, COALESCE(inhparent, pg_class.oid) parent
FROM pg_class
LEFT JOIN pg_inherit_short ON inhrelid = oid
WHERE relkind IN ('r', 'p')
) c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
) a
WHERE oid = parent
) a
ORDER BY total_bytes DESC;
Or you can use About the same
select schemaname as table_schema,
relname as table_name,
pg_size_pretty(pg_total_relation_size(relid)) as total_size,
pg_size_pretty(pg_relation_size(relid)) as data_size,
pg_size_pretty(pg_total_relation_size(relid) - pg_relation_size(relid))
as external_size
from pg_catalog.pg_statio_user_tables
order by pg_total_relation_size(relid) desc,
pg_relation_size(relid) desc;
In the case of an error, you may see a table with a full-text index that is about 500 GB in size. However, in most cases, you use elastic search for full-text search, and this index does not help, and then takes up your hard drive space. It's not very big, but if you have 100 nodes, the index will cost you 5k Euro more per month on extra hard disk space. A problem well stated is a problem half solved.
Show index or diffrence
python manage.py sqldiff job
SELECT tablename, indexname, indexdef FROM pg_indexes;
Or filtered result
select * from pg_indexes where tablename like '%job_jobarchive%';
Then find the name and size of index that you are not using and take place. You can remove them.
ALTER TABLE name DROP CONSTRAINT constran_name;
DROP INDEX index_name;
In most cases what it takes is adding extra resources and a server separately could be the solution for setup in number of years. Or a service in managed cloud if it is affordable for your project.

Comments
Post a Comment