When running the backup in the shell I immediately see that the problem is in the archive..
Back these archive jobs that actually don't belong in the database cause problems. So that is a very specific problem and I have not found a standard solution on the internet. I have developed a small command myself in python with which I have found and removed corrupt records manually via SQL. See further description of problem and method to repair.
First I convert here features and documents that I studied and after that see section Solution convert.
Plain backup of vindazo_de
pg_dump: error: Dumping the contents of table "job_jobarchive" failed: PQgetResult() failed.
pg_dump: error: Error message from server: ERROR: compressed data is corrupted
pg_dump: error: The command was: COPY public.job_jobarchive (job_id, source_unique, company_name, company_name_slug, phone, email, url, sol_url, title, description, raw_text, address, city, country, zip_code, added, last_updated, status, for_index, slug, slug_description, view, click, has_checked_duplicate, job_type, contract, statute, logo, company_id, source_id, user_id, category_text, payed, redirect, raw_text2, auto_anonymize) TO stdout;
Corrupted table postgresql
Again a problem with THE database and back archive that broke.. What exactly is the problem? See the same here..
Tried everything that could be found on the internet and failed.
REINDEX
ANALYSE
etc…
https://wiki.postgresql.org/wiki/Corruption
https://docs.google.com/document/d/1aaVA9MisQfCe-nb030rKlxluhM_d3iboilLjr1dO6o4/edit
See more docs about this bugfix, If you interested in. Or read a solution, because it is short and to the point.
Solution:
How did I fix this problem?First I saved all IDs of this table separately in a text file.
\copy (SELECT job_id FROM job_jobarchive) to 'job_id.csv' with csv;
It took about two minets to copy all IDs to a text file…
That is for sure we now have to go through all the records one after the other and try to select if an error happens then save this error and ID of a record that is not selected.. So I get records that I have to delete..
This attempt is to select all records at ID and then you may see an error.
I've done it with this command:
vim job/management/commands/find_corupted_archive_select.py
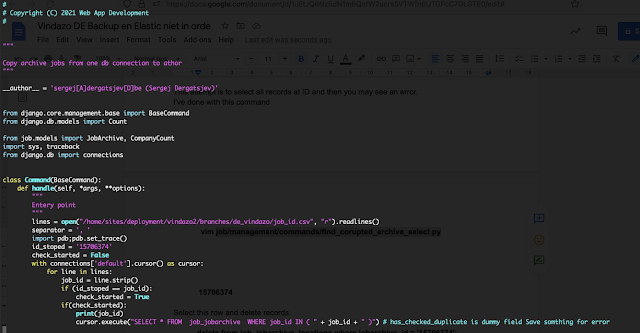
from django.core.management.base import BaseCommand
from django.db.models import Count
from job.models import JobArchive, CompanyCount
import sys, traceback
from django.db import connections
class Command(BaseCommand):
def handle(self, *args, **options):
"""
Entery point
"""
lines = open("/home/sites/deployment/vindazo2/branches/de_vindazo/job_id.csv", "r").readlines()
separator = ', '
import pdb;pdb.set_trace()
id_stoped = '15706374'
check_started = False
with connections['default'].cursor() as cursor:
for line in lines:
job_id = line.strip()
if (id_stoped == job_id):
check_started = True
if(check_started):
print(job_id)
cursor.execute("SELECT * FROM job_jobarchive WHERE job_id IN ( " + job_id + " )")
15706374
You can find it In Deployment Vindazo Germany server.. Not committed at this time in Git. I will add it in trunk maybe.
So, when you find record you can delet it via SQL client.
delete from job_jobarchive_locations where jobarchive_id = '15706374';
delete from job_jobarchive where job_id = '15706374';
REINDEX Table job_jobarchive;
Comments
Post a Comment